Why AI Projects Lose Context Between Sessions (And How to Fix It)
You build something great with ChatGPT, Claude, or an OpenClaw agent on Monday. By Wednesday, your AI has no idea what you're talking about. You spend 20 minutes re-explaining the project, re-stating constraints, and re-making decisions you already made. By Friday, you've lost an hour just getting back to where you were.
This isn't a bug. It's how every AI chat tool works by default. And it's the number one reason AI projects fail once they grow beyond a single session.
The Problem: Every Session Starts from Zero
AI chat tools — ChatGPT, Claude, Gemini, and agent frameworks like OpenClaw — treat every conversation as a blank slate. When you close a session, the context disappears. The decisions you made, the architecture you agreed on, the constraints you established — all gone.
For quick one-off tasks, this doesn't matter. Ask your AI to write an email, summarize a document, generate a function — single-session work is fine.
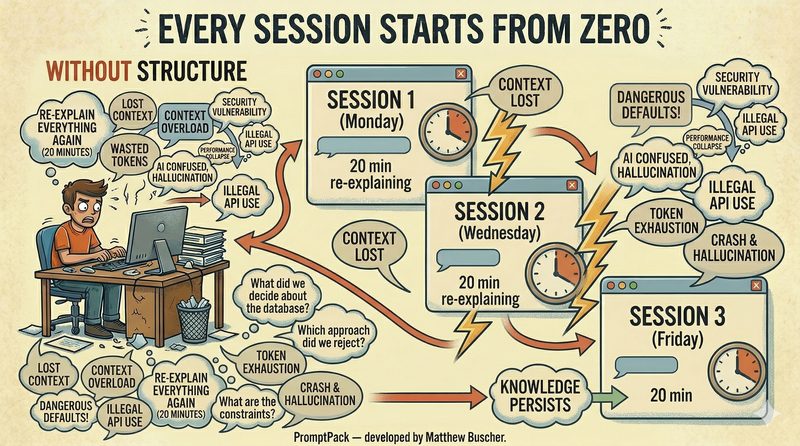
But the moment your project spans multiple sessions (which any real project does), you hit a wall. The AI doesn't remember what you decided about the database schema last Tuesday. It doesn't know you already rejected the microservices approach. It doesn't know that the client wants GDPR compliance. So it suggests things you've already ruled out, generates code that conflicts with earlier decisions, and produces inconsistent results that cost you hours to untangle.
Why Context Windows Don't Solve This
You might think bigger context windows fix the problem. They don't — they actually make it worse.
When you dump an entire project history into a prompt, your AI gets overwhelmed. Critical decisions get buried under thousands of tokens of conversation history. The AI may technically have access to the information but can't prioritize what matters right now versus what was discussed three weeks ago. This is called context overload, and it leads to unfocused, generic responses that miss the specific constraints of your current task.
OpenClaw users have seen this firsthand. Previous versions used lossy context compaction — when conversations hit the token limit, the system discarded old messages or generated rough summaries. Key decisions from early in the project simply vanished. The March 2026 ContextEngine update improved this, but it still requires developers to build custom plugins for context management.
The core issue isn't how much context your AI can hold. It's whether you have a system for deciding what context to load and when.
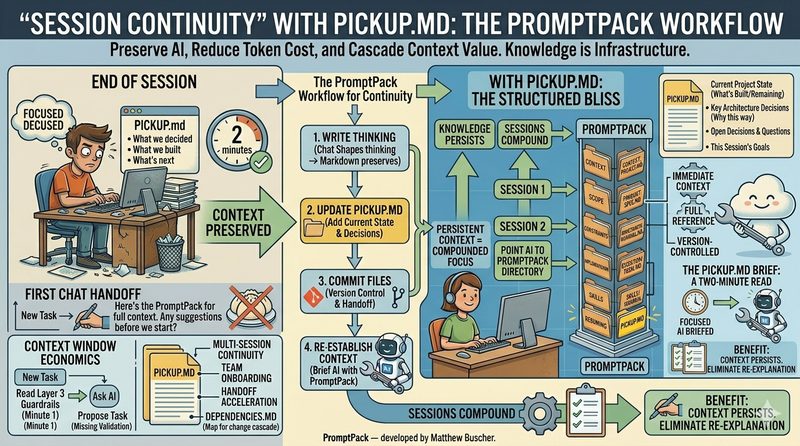
The Fix: Session Continuity with Structured Handoffs
Session continuity is the practice of maintaining project context across separate AI chat sessions using structured handoff documents. Instead of relying on the AI to remember (it can't) or dumping everything into one prompt (it chokes), you capture the state of your project in a document that your AI reads at the start of every session.
The simplest version of this is a file called PICKUP.md. At the end of every work session, you (or your AI) write a short document that answers five questions:
1. What did we work on? A one-paragraph summary of the session.
2. What did we decide? The three to five key decisions made during the session.
3. What did we complete? Deliverables, files created, milestones hit.
4. What's blocked? Anything waiting on external input.
5. What's next? The immediate next actions for the following session.
At the start of your next session, you feed your AI the PICKUP.md file. It reads the summary, understands the current state, and resumes where you left off. No cold starts. No re-explaining. Five minutes of writing saves twenty minutes of context restoration — every single session.
Progressive Disclosure: Load What Matters, When It Matters
Session continuity handles the "between sessions" problem. But there's a deeper structural issue: how do you organize the full context of a project so your AI can access the right information at the right time?
The answer is progressive disclosure — a 6-layer system for loading context in stages that match the development progression of your project:
Layer 0 — Foundation: Project identity, audience, constraints, success criteria. What are we building and why?
Layer 1 — Planning: Vision, roadmap, phased approach. What's the plan?
Layer 2 — Specification: Feature specs, user stories, acceptance criteria. What exactly does each piece do?
Layer 3 — Design: Architecture, data models, API contracts. How is it structured?
Layer 4 — Execution: Code, content, implementation. Build it.
Layer 5 — Quality: Testing, validation, refinement. Does it work?
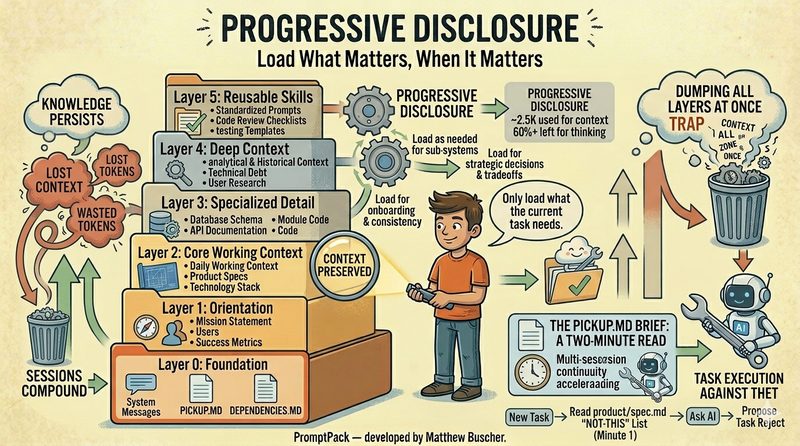
When you're at the design stage, your AI doesn't need to see every test case from Layer 5. When you're writing specs, it doesn't need the full codebase from Layer 4. Progressive disclosure means loading only the layers relevant to your current task, preventing context overload while keeping your AI informed and focused.
Canonical Structure: Same Layout, Every Project
The third piece is standardization. Every project should use the same folder structure: context, product, constraints, execution, quality, and skills. When your AI knows where to find things because the structure is always the same, it can navigate the project without you explaining the layout every time.
This also makes projects searchable across a team — anyone can open any project and immediately know where to look for specs, decisions, constraints, or deliverables.
This Works with Any AI Tool
Because this system uses plain markdown files, it works with any AI that reads text. ChatGPT, Claude, Gemini, Copilot, Cursor, OpenClaw — the methodology is platform-agnostic. Your project structure lives on your file system, not inside any vendor's product. If you switch AI tools tomorrow, your project context comes with you.
Stop Losing Context. Start Compounding.
PromptPack provides the templates, folder structure, and handoff documents that make this system work out of the box.
Get PromptPack →